Supervised learning, the most developed form of machine learning, starts with the preparation of labeled training data that are rich and representative (e.g., a large number of typical “spam” or “normal” emails). The machine teaches itself with these examples, such that it can label new data (i.e., new emails) that are unseen but similar to the training data. If the new data turned out to be different (say, spams with other patterns), typical advice would be to enrich the training set, such that it reflects the real process that generates the data we would like to label.
The above approach works that way because the ultimate goal there is to automate the labeling of new data, as accurately as possible. But, accurate automation on new data is not always the goal. What if, instead, we are interested in the discrepancy between the training data and new data?
In a new research paper, “Reading China: Predicting Policy Change with Machine Learning,” we show that machine learning, with a twist, can uncover structural changes underlying complex data. We train a neural network algorithm that “reads” the People’s Daily, the mouthpiece of the Communist Party of China, and classifies whether each article appears on the front page — part of the People’s Daily editor’s job. It turns out that such an algorithm can be used to detect changes in the newspaper’s issue priorities, which, in turn, have profound implications for China’s government policies.
The algorithm tries to mimic the mind of an avid People’s Daily reader who reads its articles and tries to figure out how its editor prioritizes them. If the reader had digested, say, five years’ worth of articles, they would be able to say, with a certain degree of confidence, what’s on the editor’s mind and what kind of articles do or do not “deserve” the front-page status.
But what we are really interested in is whether such an editorial paradigm has shifted over time. To answer this question, suppose the reader applies the paradigm acquired from the five years of observations (the training data) on the articles published in the next quarter (the new data). The reader may be surprised by the new articles; their educated guess about the front page may turn out exceptionally good or particularly poor — a signal of change. While a small surprise may well be taken as noise, a strong signal would convince the reader that their understanding of the editor’s mind is no longer valid and that the priorities of the People’s Daily have fundamentally changed.
We construct a quarterly indicator, which we call the Policy Change Index (PCI) of China, that captures the amount of surprise the algorithm has in each quarter, compared to the previous five years. The key to the design of the PCI is the realization that changes in underlying patterns come from the discrepancy — not the consistency — between what the algorithm has learned and what it will encounter.
The namesake of the indicator comes from the fact that detecting changes in the newspaper’s priorities allows us to predict changes in the Chinese government’s policies. This is because the People’s Daily is at the nerve center of China’s propaganda system, an essential function of which is to mobilize resources to attain the government’s policy goals. Moreover, before major policy changes are made, the government often finds it necessary to justify to or convince the public that those changes are the right moves for the country. Hence, while our algorithm is detecting propaganda change in real time, it’s really predicting policy changes for the future.
When put to the test against the ground truth — policy changes in China that did occur in the past — the PCI could have correctly predicted many of the most critical junctures in the history of China’s economy and reforms. These major changes include the beginning of the Great Leap Forward in 1958, that of the economic reform program in 1978, and, more recently, a reform speed-up in 1993 and a reform slow-down in 2005, among others.
Once we allow for the discrepancy between the training data and new data, the machine learning tools open the door to a variety of applications where detecting structural changes in complex data is the central question.
The interested reader can find more details about China’s policy changes, our methodology, and its potential applications in our research paper or the website of our project. We have also released the source code of the project on GitHub, so that the academic, business, and policy communities can not only replicate our findings but also apply our method in other contexts.

Julian TszKin Chan
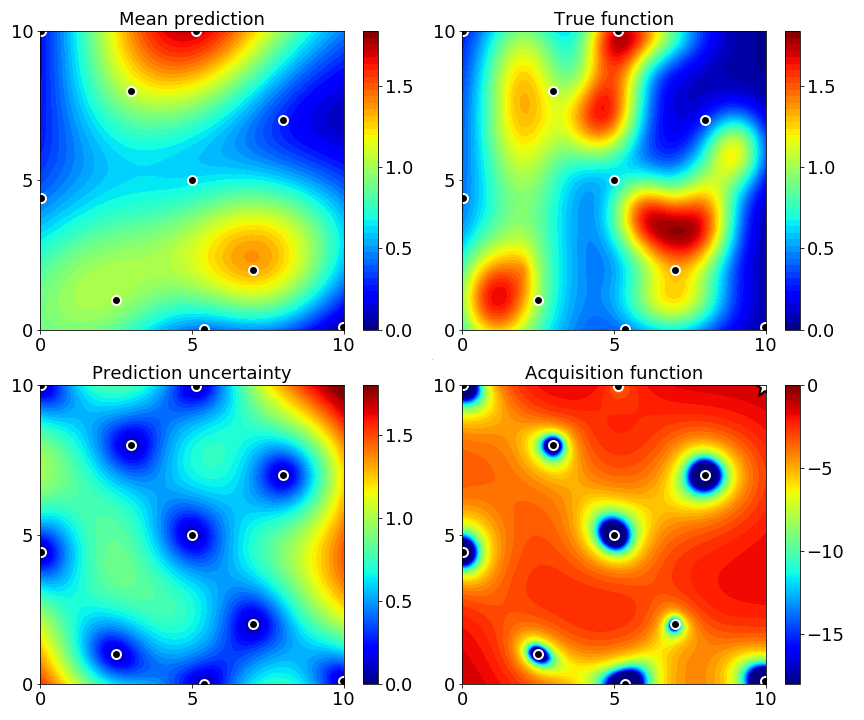
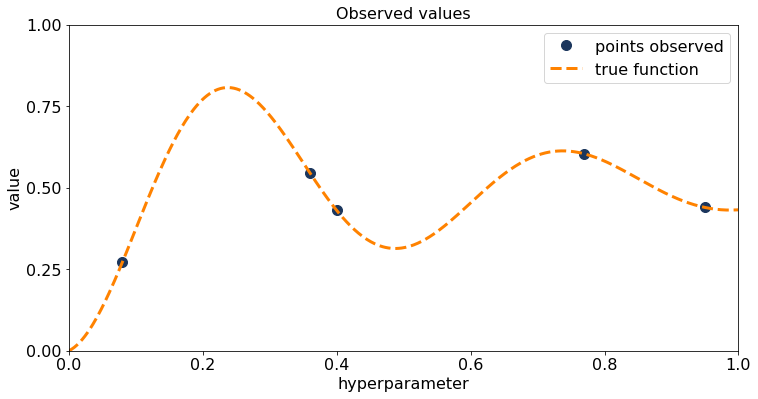


 Figure 1
Figure 1