As a machine learning practitioner, “Bayesian optimization” has always been equivalent to “magical unicorn” that would transform my models into super-models. So off I went to understand the magic that is Bayesian optimization and, through the process, connect the dots between hyperparameters and performance.
Through hyperparameter optimization, a practitioner identifies free parameters in the model that can be tuned to achieve better model performance. There are a few commonly used methods: hand-tuning, grid search, random search, evolutionary algorithms and Bayesian optimization. Hand-tuning is a manual guess-test-revise process that relies on a practitioner’s previous experience and knowledge. A grid search exhaustively explores configurations until a reasonable accuracy has been reached. Random search uses random samplings of all possible combinations of all hyperparameters. And evolutionary algorithms use the comparison of “mutation-like” configurations with the best performing configurations to iterate on the model parameters. The goal of each of these methods is to find the global optima of hyperparameter values.
The problem, however, is that each of these methods has a fatal flaw. Hand-tuning results may not be reproducible from practitioner to practitioner, and the process is difficult to scale. Grid search cannot efficiently optimize models with more than 4 dimensions, due to the curse of dimensionality [5]. Although random search is more capable than grid search, its naive approach is still both time-consuming and expensive and is more likely to settle in a local optima. Furthermore, it is unscalable beyond 10 parameters [5]. Evolutionary algorithms are great if you have access to nearly unlimited compute that can be run in parallel, but is often difficult to implement if you do not.
Bayesian optimization democratizes access to these algorithmic superpowers by relaxing each of these constraints. Originally popularized as a way to break free from the grid, Bayesian optimization efficiently uncovers the global maxima of a black-box function in the defined parameter space. In the context of hyperparameter optimization, this unknown function can be the objective function, accuracy value for a training or validation set, loss value for a training or validation set, entropy gained or lost, AUC for ROC curves, A/B test results, computation cost per epoch, model size, reward amount for reinforcement learning, among others. Here is a quick visual summary of how Bayesian optimization works:
Step 1:
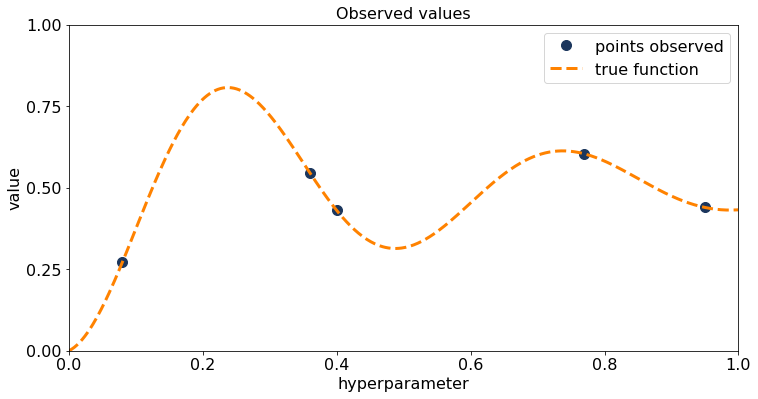
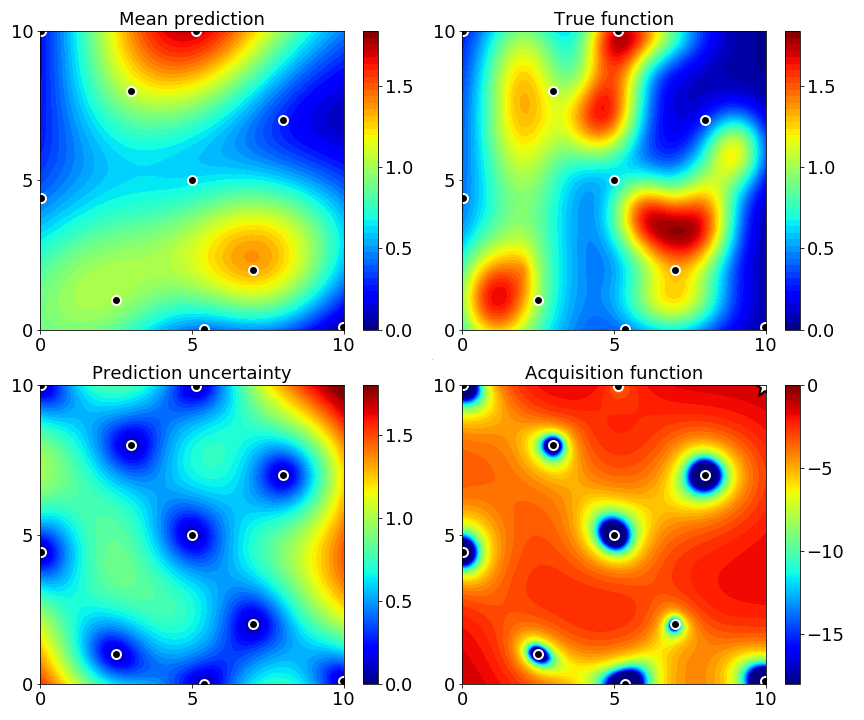
Initialize process by sampling the hyperparameter space either randomly or low-discrepancy sequencing and getting these observations [3].
Step 2:

Build a probabilistic model (surrogate model) to approximate the true function based on given hyperparameter values and their associated output values (observations). In this case, fit a Gaussian process to the observed data from step 1. Use the mean from the Gaussian process as the function most likely to model the black box function.
Step 3:
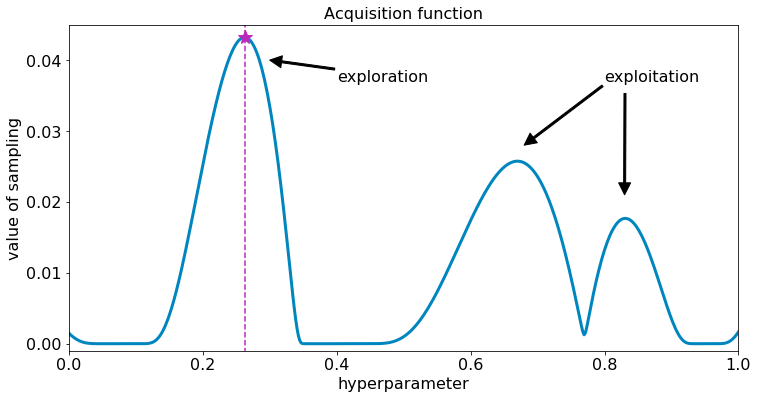
Use the maximal location of the acquisition function to figure out where to sample next in the hyperparameter space. Acquisition functions play with the trade-off of exploiting a known maxima and exploring uncertain locations in the hyperparameter space. Different acquisition functions take different approaches to defining exploration and exploitation.
Step 4:

Get an observation of the black box function given the newly sampled hyperparameter points. Add observations to the set of observed data.
This process (Steps 2-4) repeats until a maximum number of iterations is met. By iterating through the method explicated above, Bayesian optimization effectively searches the hyperparameter space while homing in on the global optima. [6, 1, 2].
There are a variety of attributes of Bayesian optimization that distinguish it from other methods. In particular, Bayesian optimization is the only method that
- Adaptively and intelligently explores a hyperparameter space with optimal learning.
- Explore and exploit to find global optima [6, 2].
- Robustly handles noisy data.
- Optimally searches non-continuous and irregular spaces.
- Efficiently scales with hyperparameter domain.
- Maximizes utilization of computing resources.
How does this work in practice? Consider a CNN architecture for sentiment analysis [4]. This experiment tunes hyperparameters for each component of the modeling process from preprocessing (embedding dimension) to architecture (filter sizes and feature maps) to training (learning rate and dropout), and compares the results of random search, grid search, and SigOpt’s proprietary set of Bayesian optimization algorithms. The results are as follows:
| Experiment Type | Accuracy | Trials | Epochs | CPU Time | CPU Cost | GPU Time | GPU Cost |
| Default (No tuning) | 75.70 | 1 | 50 | 2 hours | $1.82 | 0 hours | $0.04 |
| Grid Search (SGD Only) | 79.30 | 729 | 38394 | 64 days | $1401.38 | 32 hours | $27.58 |
| Random Search (SGD Only) | 79.94 | 2400 | 127092 | 214 days | $4638.86 | 106 hours | $91.29 |
| Bayesian Optimization Search (SGD Only) | 80.40 | 240 | 15803 | 27 days | $576.81 | 13 hours | $11.35 |
| Grid Search (SGD + Architecture) | Not Feasible | 59049 | 3109914 | 5255 days | $113511.86 | 107 days | $2233.95 |
| Random Search (SGD + Architecture) | 80.12 | 4000 | 208729 | 353 days | $7618.61 | 174 hours | $149.94 |
| Bayesian Optimization Search (SGD + Architecture) | 81.00 | 400 | 30060 | 51 days | $1097.19 | 25 hours | $21.59 |
From the above results, we see that tuning beats no-tuning, with a max of 5.3% increase in accuracy. It is also clear that Bayesian optimization beats grid and random search in accuracy, cost and computation time on both CPU and GPU. Bayesian optimization is able to achieve around a 1-2% boost in accuracy compared to grid and random search for 12%-14% the cost of random search on CPU and GPU. Furthermore, Bayesian optimization arrives at the global optima in a fraction of the time, allowing you to test out more models and architectures. This is only one data point, but we see this pattern of Bayesian optimization being more skillful and powerful replicated in scenarios such as regression models, reinforcement learning, unsupervised learning, and deep learning. Here is more information on common problems with hyperparameter optimization and how to evaluate hyperparameter optimization strategies.
Now that I’ve convinced you to use Bayesian optimization for your hyperparameter optimization, here are some tips to make Bayesian optimization easy.
- Choose the right metric or metrics to optimize
- Engineer around parameterization for easy tuning
- Consider tuning as an integral part of your ML workflow instead of a final step of your modeling
At SigOpt, we’ve created an easy to integrate and easy to use API that also supports advanced Bayesian optimization methods such as constraints, conditional parameters, multi-metric optimization, and parallelism. Happy modeling!
References
[1] E. Brochu, V.M. Cora, N. de Freitas. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. CoRR, abs/1012.2599, 2010.
[2] P. Frazier. Bayesian Optimization. Recent Advances in Optimization and Modeling of Contemporary Problems, October 2018.
[3] M. W. Hoffman, B. Shahriari. Modular mechanisms for bayesian optimization. In NIPS Workshop on Bayesian Optimization, 2014.
[4] Y. Kim. Convolutional Neural Networks for Sentence Classification. In Proceedings of ACL 2014. June 2014.
[5] I. Dewancker, M. McCourt, S.Clark, P. Hayes, A. Johnson, G. Ke. A Stratified Analysis of Bayesian Optimization Methods. arXiv:1612.04451. December 2016.
[6] B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. de Freitas. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1):148–175, Jan 2016.
Thank you to essential contributions from Harvey Cheng, Alexandra Johnson, Mike McCourt, Kevin Tee.