Many commercial applications of Deep Learning need to operate at large scale, typically in the form of serving deployed models to large numbers of customers. However inference is only half of the battle. The other side to this problem, which we will address here, is how to scale ML model building and research efforts when training datasets grow very large, and training must be done in a distributed fashion in the cloud. At Intuition Machines, we often need to deal with web-scale datasets of images and video, and as such having an efficient, scalable multi-user distributed training platform is essential.
This post encapsulates our recent review of the field, and is intended to serve as an introduction to the principles of training at scale along with a brief overview of the best available open source solutions for training your own networks in this manner.
WHAT ARE THE CHALLENGES WITH SCALING UP DEEP LEARNING?
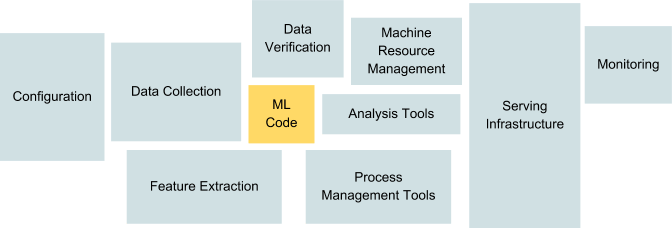
As ML projects move from small scale research investigations to real world deployment, a large amount of infrastructure is required to support large scale inference, efficient distributed training, data ingest/transformation pipelines, versioning, reproducible experiments, analysis, and monitoring; creating and managing these support services and tools can eventually constitute much of the workload of ML engineers, researchers, and data scientists.
The portion of ML code in a real-world ML system is a lot smaller than the infrastructure needed for its support.
Source: Sculley et al.: “Hidden Technical Debt in Machine Learning Systems”
How can we enable these teams to focus on training the best models and delivering the best solutions without reinventing the wheel each time or getting bogged down in technical debt? (Sculley et al. discuss some other challenges in scaling ML systems, such as Glue Code, Pipeline Jungles, Reproducibility and Process Management Debt). We will take a look at some of the emerging infrastructural solutions to combat these issues below.
These days it is common to use cloud compute services such as Amazon AWS, Microsoft Azure, or Google GCP for handling all kinds of workloads. On the inference and data processing side, we can efficiently handle massive jobs in parallel using clusters of worker nodes and services co-ordinated with Kubernetes. We can be agnostic to underlying hardware and deploy on different platforms, using containerization to manage installation requirements.
For training, Deep Learning packages such as TensorFlow and PyTorch have added native support for multi-GPU training. This may be straightforward enough to deploy on a small scale on dedicated hardware, but when dealing with multi-node distributed training additional work is required. Another big requirement is portability: the same code should run on a laptop, a GPU rig, or a cluster, and even automatically scale based on demands. It is possible to hand-craft scripts to orchestrate deployment across a cluster, but this is cumbersome. However there are now open-source solutions that will enable packaging, containerization and automated deployment and co-ordination of workers and jobs. We will look at some in the next section.
Beyond distributed training of a single model, there are other requirements to make a truly efficient, repeatable, and flexible pipelined system for the whole ML workflow. When researchers are tackling new problems and investigating new models, it pays to have infrastructure in place that supports some of these tasks in order to streamline the process:
- Data ingest, serving, versioning, preprocessing, splitting, transforms / augmentations
- Job packaging and deployment; job reproducibility
- Experiment monitoring/logging; comparison of results across runs, status dashboards
- Automated hyperparameter tuning and model architecture search
- Rapid deployment from training to online model serving / inference, and A/B testing
- Support a wide variety of Deep Learning frameworks and other libraries in an integrated fashion, to avoid imposing limits on researchers enabling diverse solutions to be tried
Overall, the goal is to iterate and search over a variety of methods, models, features, and data pipelines in a manageable, repeatable, and measurable way, rather than trusting the more ad-hoc approaches that are common to many small research labs. Ideally after we have set up the processes for managing these components, the whole process becomes straightforward for researchers or data scientists to use the deployed environments in a self-service fashion, and to work collaboratively sharing a common resource pool of cluster nodes.

Some core architectural components of the ML workflow.
There are a large number of commercial solutions being touted to manage the ML lifecycle, such as RiseML, H20 Driverless, Anaconda Enterprise, Databricks, Paperspace, Domino Data Lab, ParallelM, neptune.ml, and comet.ml. Many of these platforms are also built around Kubernetes. There are also useful hosted platforms available on the major public cloud services, such as Microsoft’s Azure Machine Learning Service (formerly BatchAI), Amazon’s SageMaker, and Google’s Cloud AI, which help with some of these requirements.
Many large organizations have also developed their own private internal solutions to these problems, for example FBLearner Flow (Facebook), MichelAngelo (Uber), TFX (Google).
However, we are big fans of open source (having open sourced portions of our hCaptcha system and HUMAN protocol) and contribute to dozens of open source projects that we use internally. Therefore rather than using a hosted commercial service, or developing our own from scratch, our preference was to see what open source equivalent solutions are emerging in the ML infrastructure space. There are a variety of requirements here which may be handled by a single package, or a combination of several, which we will describe next.
SOME OPEN SOURCE ML INFRASTRUCTURE SOLUTIONS
The Jupyter notebook paradigm has become popular among researchers and data scientists for rapidly iterating (especially Python) code, visualizing results, and experimenting with different models. JupyterHub allows hosting multiple users with their own notebook servers; it is designed to be flexible, scalable and portable, and can be deployed with Kubernetes.
A project that originated at Google, Kubeflow began with the aim of making it easy to run TensorFlow jobs on Kubernetes, and is expanding to support a whole stack of other ML and infrastructure tools. These include:
- TFJob – a resource/YAML file spec describing how to run a (possibly distributed) TensorFlow job on Kubernetes
- Argo – Build container-native workflows on Kubernetes (every step of the workflow is a container). For example, build reusable containers automatically from trained models.
- Seldon-core – model deployment via Docker; convert to microservices with REST/gRPC APIs; A/B testing; and manage deployed inference scalably.
- TF Serving – another library serving models for inference, A/B testing, model versioning
- Istio – metrics, A/B testing and integration with TF serving
- Katib – Black Box Hyperparameter tuning, in the vein of Google Vizer
- Ksonnet is used as an alternative to Helm for Kubernetes package management.
At the Deep Learning framework level, Kubeflow has been adding support for MXNet, PyTorch and Chainer as well as TensorFlow. Jupyterhub is also available as a component.
There are clearly a large number of separate components which are really standalone projects, with some overlaps and some gaps. The Kubeflow project, while more or less usable at the time of writing, is still under heavy development and requires a large investment of engineering time into understanding the system, configuring it for your needs, and often patching a few areas you need but no one has touched recently to make the most of everything in a truly integrated fashion, and to support multiple users dynamically.
Our view is that there is a lot of vision here and hopefully the pieces will come together rapidly as the project evolves. However, for larger organizations with distributed systems expertise it brings less benefit than you might expect due to the immaturity of the codebase and heavy churn. Without having a Kubeflow maintainer on staff, using it for non-trivial work may be difficult to justify and will certainly require a substantial time investment.
Another integrated platform built on top of Kubernetes, that has an emphasis on reproducible ML at scale, in a simple and accessible way. It is somewhat more aligned to the goals of a self-service multi-user system, taking care of scheduling and managing jobs in order to make best use of available cluster resources. It also handles code/model versioning, automatic creation and deployment of docker images, and can support auto-scaling.
It provides features such as distributed model training, experiments, dashboards with visualization, metrics, and easy hyperparameter optimization. Polyaxon supports various DL frameworks including Tensorflow, Keras, MXNet, Caffe, PyTorch. Currently there is no built-in support for model serving, with more of an emphasis on experimentation and inference, but new features are being added rapidly.
Compared to Kubeflow, Polyaxon is very focused. Polyaxon doesn’t attempt to cover realtime serving, istio integration, has no ksonnet requirement, and isn’t tightly tied to seldon. Rather polyaxon is more focused on running adhoc or repeatable experiments. It does handle all of the package management and can automate notebook and tensorboard installs. Polyaxon solves the problem of running disparate jobs on the same cluster and it supports distributed training as well. It has a built in job management dashboard, as well as simple user management.

Polyaxon sits on top of Kubernetes services to provide an easy-to-use, repeatable ML experimentation and training platform, supporting dashboards, versioning and much more.
Source: https://docs.polyaxon.com/experimentation/concepts/
IBM’s Fabric for Deep Learning (pronounced “fiddle”) is a Kubernetes based platform designed around elastic, cloud based distributed training, and abstracting some of the complexities of the underlying infrastructure to move towards “Deep Learning as a service”. It supports many of the main DL frameworks – Tensorflow, Keras, Caffe 1&2, and Torch, and makes use of Jupyter, Docker and Helm, and is designed around S3 based data and model storage. It provides a Grafana dashboard for monitoring jobs, and can use Horovod for distributed training. Manifest files are used to describe a model to be trained, hyperparameters, resource requirements, metrics, etc. REST APIs are used to interface with a gRPC Trainer, which stores jobs in a database, and handles scheduling multi-user training jobs across their life cycles, as well as parameter servers. There is a training data service to manage metrics and logs. For model deployment, integration with Seldon is supported.

Architecture of FfDL
Source: https://github.com/IBM/FfDL
This python framework was recently open sourced by Instacart, and is more of an easy to use workflow solution for the ML training and inference pipeline. It supports hyper-parameter search, data extraction, encoding and splitting pipelines, database connections, dependency management, CI/CD testing, model deployment, and integration with packages such as Keras, Tensorboard, Scikit-learn and Jupyter. One key idea is to standardize ML practice across different libraries, with a set of wrappers. There is perhaps more of an emphasis towards time series/textual data than video and images and CNN model based Deep Learning, and it doesn’t get into the world of containerization and cluster management.
As such, it is perhaps a good entry point for newcomers to the field who look for some of the consistency and workflow solutions we have been describing, but it perhaps lacks some of the more advanced features that are useful for an organization doing large scale distributed training and architecture search on visual domain data.
An open source library created by Databricks, designed for managing 3 stages of the ML lifecycle: Tracking, Projects, and Models. The goals of the project are to improve reproducibility and enable experiment tracking, and make it easier to move models to production. It is also designed to support any Python or R based ML framework, has a web UI to make tracking straightforward, and has multi-user support by running a tracking server. Tracking supports metrics, visualizations, storing artifacts, and comparing runs, as well as hyperparameter tuning. Projects support a simple way of packaging code, run parameters, and dependencies via YAML configuration files and Conda environments, and integration with Git. Projects also support scalable dataset I/O with hosts like AWS S3. Models can easily be deployed in several ways, including as a REST server, or exported into a Docker container,
Overall, it is easy to get started with a single-user local setup, but still has scalability to support larger datasets and teams. Distributed training or cluster support is not part of the functionality however, so additional work will be required here.
This Python package from Sentient is designed to manage ML model building experiments, covering some of the same ideas as ML Flow or Lore, without deployment, but with some cloud-based training integration. It supports the most common packages – Keras, TF, PyTorch, and scikit-learn. Its main features include environment and dependency management, monitoring/logging, experiment management, hyperparameter search, artifact management, and containerization. One of its unique features is it has direct integration with Amazon EC2 and Google Cloud APIs, as well as auto-scaling to make launching its training jobs on these platforms straightforward.
Airbnb recently presented their new open-source end-to-end ML pipeline library. As of the time of writing it has not yet been released, but looks very promising. It covers features across the whole workflow from data ingest/transformations, training, model management, hyperparameter tuning, monitoring and deployment. It is designed to be modular and support common ML training frameworks. There is support for built-in data transformations and data visualization tools, to help with one of the parts of the ML development process where researchers and engineers spend most of their time. Its Redspot environment is an extension of JupyterHub that helps with instance and package management, and built around automated Docker container services, which helps with the training workflow and multi-user environments. Model management keeps model code and trained models in sync, and improves reproducibility through common metrics. Production supports scalable streaming and brings consistency between training and deployment environments.
There is a lot of promise here, though we will have to see how everything behaves in practice once released.
Data
On the data ingest, processing, management, and retrieval fronts, there is a lot more than can be covered in detail here, in terms of how to effectively deal with training datasets once their scale outgrows what can be stored on a single node. For now we are making use of custom solutions in these areas, but there are a couple of packages worth pointing out.
The ability to transform data using different pipelines is an essential part of the ML process. In experimentation, data engineering is often as if not more important than model design. As models and data evolve in parallel, many organizations face the problem of repeatability and versioning of datasets along with models. But it’s not possible just to store huge datasets in git. So packages such as Pachyderm enable data provenance, i.e. where did the data come from, and how has it been modified along the way. As data is ingested from different locations, cleaned, augmented, and transformed with different methods, version control can be applied, so that experiments can reveal if it was changes to the dataset or to a model that caused an improvement. Some of this may be seen as overkill in certain workflows, but with data being a key part of the whole ML process, it’s worth thinking how to integrate these approaches with experiment tracking, for instance. Pachyderm is also built around Kubernetes and can be integrated with Kubeflow.

Pachyderm allows data versioning and persisted model workflows.
source http://docs.pachyderm.io/en/latest/cookbook/ml.html
A library for image data augmentation. Often necessary in Computer Vision tasks, the ability to apply various parametric transformations to an image dataset can be a bottleneck in training. Being able to do this in a fast and streamable manner is a useful component.
In keeping with the trend of using Kubernetes and Docker based microservices, the idea of Functions as a Service is a scalable way to create customized data processing pipelines from existing functional components, in a Serverless fashion. We have been investigating these approaches and integrating with other systems; this appears to be a flexible and robust way to handle large scale data processing requirements for both training and inference.
Distributed training
The solutions described so far help with managing training workflow, but taking advantage of additional compute power that a cluster can provide to give faster training results requires some changes to training code in order to transfer weight updates in stochastic gradient descent between workers. There are a couple of solutions that avoid having to hand-roll some of this process.
Distributed Tensorflow has capabilities for using a parameter server to manage distributed jobs. This requires specification of a ClusterSpec, containing IP addresses/ports of servers where the tasks should run. Projects like Kubeflow (via TFJob files) or Polyaxon can help set this up, on top of a Kubernetes cluster. This still requires a degree of interaction with the cluster setup itself. Some additional scripting is required for example to automate packaging.
While the approach used by TensorFlow is typically to use a parameter server in order to manage
weight updates in a distributed training scenario, Uber’s Horovod library takes things to another level of performance and ease of use. It uses a different manner for averaging weights’ gradients across workers. Rather than all weights being averaged through a central parameter server, workers exchange only a portion of their gradient updates with their neighbors using a ring-allreduce algorithm, that makes much more efficient use of network bandwidth. It uses a Message Passing Interface like Open MPI, as well as using NVIDIA’s NCCL library to optimize these transfers both on a single Multi-GPU machine, as well as on a cluster.

Horovod uses the ring-allreduce algorithm to enable efficient distributed training without the need for a centralized parameter server
Source: https://eng.uber.com/horovod/
In terms of ease of use, there are only a few commands to inject into standard training code in order to support training in this way – standard optimizers are wrapped in a custom distributed version. Support was available for Tensorflow and Keras originally but now PyTorch sessions can be distributed in the same way.
Horovod has already proved itself in providing an effective enabling technology, and we would be excited to see it be natively supported by more of the ML lifecycle solutions.
Our use
At Intuition Machines, we are not strangers to the challenges of Machine Learning (ML) at scale. We have become experts at providing very large scale, efficient inference and data retrieval solutions to our clients, with a focus on Computer Vision, Images and Video.
For these tasks, we currently bootstrap our Kubernetes in Azure, and we use a combination of GPU nodes and virtual nodes to scale our laboratory cluster. We are integrating Polyaxon, with basic single sign on to manage our experiments, having easy access to the cluster. This provides a simple mechanism for users to start with a Jupyter notebook, and quickly transition it to distributed, large scale jobs, complete with experiment tracking and hyperparameter searches.
On the data side, we considered Pachyderm, which is more of a Hadoop rebuilt from scratch, and comes with some of the same downsides. Although Pachyderm is focused on “the data” it has its own mechanisms for processing this data. We currently already have a preprocessing pipeline, and we also use OpenFaas and an in-house system called Mongoose to process our large datasets resident on S3; integrating Pachyderm’s processing system so far didn’t buy us a lot.
Summary
Many of these packages, libraries and solutions have appeared during the last year, and most are still in Alpha or Beta stages. We expect to see them develop rapidly over the coming months. However, many are already in a state where they are useful for improving the real world workflows that many ML teams are facing. Larger organizations with more sophisticated requirements (especially on the data ingest side) will most likely benefit most from picking individual pieces to integrate into their preferred workflows rather than adopting opinionated and early-stage bundled solutions like Kubeflow.
Broadly speaking, we see that some of these solutions are designed with cloud-based training in mind while others are focused more on making the end-to-end ML workflow simpler for a single user system or a small research team. We are particularly excited to use solutions based around Kubernetes for the ability to make dynamic use of cloud resources, and efficiently deploy distributed training on a large scale.
However, smaller teams without in-house DevOps talent may be best served by choosing one of the simpler hosted solutions like Azure Machine Learning Service or Google Cloud ML Engine at the moment. Larger shops with more complicated needs are likely to find that the complete open source systems available are still very much in progress, and so picking and choosing components that add value on their own to plug into existing internal infrastructure will often be the most practical route for the near future.