Machine Learning is Reinventing Computer Vision Inspection on the Assembly Line
You don’t have to be plugged into the manufacturing space for very long before you hear the terms “computer vision” and “machine learning.” Both technologies are playing a big part in the advances going on in manufacturing, but at Instrumental, we believe that machine learning techniques can dramatically improve upon the traditional computer vision techniques used today. In this article, we’ll focus on a couple realistic cases to demonstrate the practical implementations of these two technologies, and how they can benefit you on the assembly line.
From Human Vision to Computer Vision:
In many factories, inspecting units involves laying down a transparency with physically-drawn lines onto a computer screen, and having a human operator attempt to tell if the unit falls within these guidelines. Traditional computer vision automates and improves upon this process by relying on a “list” of human-constructed rules for it to check and follow. As an example, consider a product with a thin cosmetic gap. There’s a little margin of error, but a gap that’s too big or too small will ruin the product’s aesthetic. A computer vision algorithm can include parameters for edge detection — where the gap should be and what the maximum and minimum allowable size are — enabling a computer to determine if the unit is within specification or not. For other applications on the same product, you would need to specify and to write separate algorithms. During this process, you would need to have foresight into all the different ways those features could appear, and train the algorithm with a set of golden and failing units.
“A computer vision algorithm can include parameters for edge detection — where the gap should be and what the maximum and minimum allowable size are — enabling a computer to determine if the unit is within specification or not.”
Computer vision has several benefits on the assembly line. With modern programs, automatic inspection of units using computer vision means that more mistakes are caught before units ramp into mass production. Part orientation, presence detection, part dimensions, and angles of part geometries can be checked according to your specifications. If your computer vision program finds errors more quickly than human operators can, this translates into less time and resources wasted in the factory.
Machine Learning:
The Achilles’ heel of computer vision, however, is the rules-based system it must follow, which makes foreseeing future issues highly dependent on past mistakes. If a specific hypothetical product defect isn’t included in the rules, or if new changes to a design haven’t been taken into account, then computer vision can give false passes and false negatives.
In contrast, consider a standard machine learning machine model, where a dataset is used to “train” the model instead of telling the algorithm what rules it should follow. Specifically, the algorithm uses a set of training data that contains the “result” you want, and uses it to build a model that creates the rules. This means that a machine learning model intended to catch defective units develops its own guidelines to identify defects, even if the specific type of defect was not trained. And let’s face it — as an engineer, it’s the defects we didn’t anticipate that are some of the most important to catch and to understand.
Instrumental has taken traditional machine learning a step further. Our anomaly detection software, Detect, leverages Convolutional Neural Networks and unsupervised learning to train the model as it is exposed to new units from the factory line. Unsupervised learning typically requires large training sets to work, with minimum sample thresholds set as large as 100K or 1M images; Instrumental Detect, however, starts working after seeing only 30 images. Most importantly, no Golden Unit is required.
Examples:
Let’s compare computer vision and machine learning on the assembly line with a couple realistic scenarios:
1) Measuring Gaps
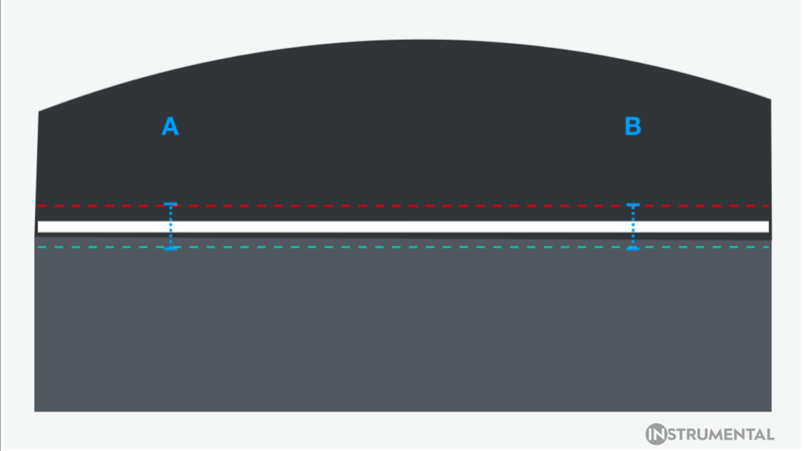
Gap measurement is a canonical use case for computer vision. A standard off-the-shelf algorithm finds edges, compares to an overlay, and gives feedback as to whether the distance between edges exceeds the allowable overlay. Custom computer vision algorithms use Hough lines or another common method to find product edges and to measure between them. They can also measure the gap in different locations and enable a specification on the delta from location to location. That gap measurement and the overall delta would be the “rules” that enable the algorithm to identify defective units.
In addition to doing all the things a custom computer vision algorithm can do, a machine learning algorithm can pick up abnormalities that were unanticipated or that are difficult to write rules around, such as contamination, flashy edges, or scratches and dents.
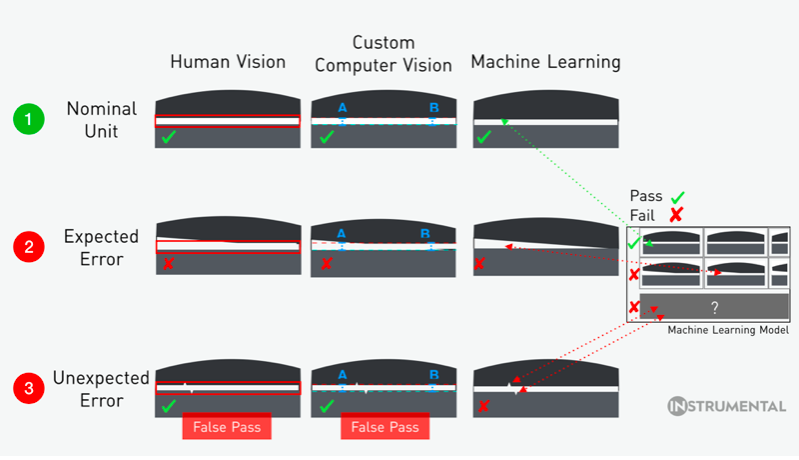
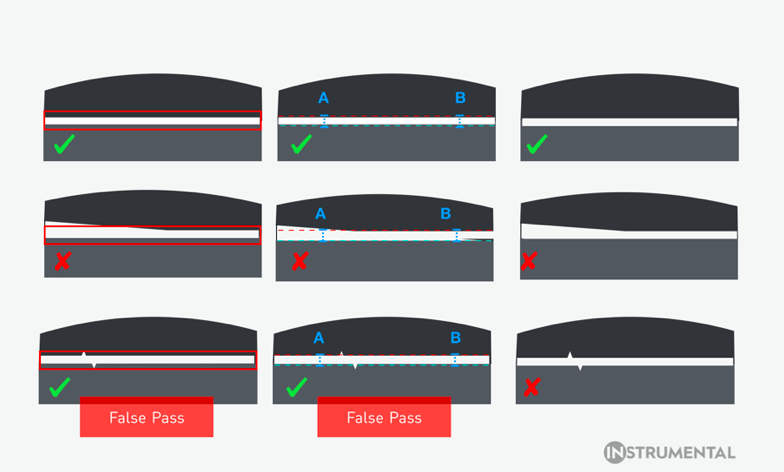
On the first row, the product has a reasonable gap size, and correctly passes inspection for a human test, computer vision, and machine learning. On the second row, the product has a tilted gap, and correctly fails inspection by all three possible methods on the assembly line. On the third row, two small jagged edges fall within rough overlay specs given to workers on an assembly line, incorrectly passing brief human inspection. Computer vision also falsely passes this unit, as the jagged edges aren’t detected by gap testing at points A and B. Machine learning, however, detects the jagged edges as something it hasn’t seen before, and flags the unit for additional review.
2) Measuring Profiles or Organic Shapes
Organic shapes are a much tougher challenge to tackle for computer vision. When trying to see if a nonlinear shape is aligned in a desired pattern, off-the-shelf computer vision algorithms no longer cut it. Instead, customization is needed to tailor the algorithm to the specifications of your product. It’s certainly possible to use complex systems and try to wrap margins of error around shapes, but the extra customization can still fail depending on how the curvature or necessary margins of error look. In addition, each time the design or fixturing of a product changes, the computer vision algorithm must be tweaked with additional rules to correctly match new dimensions. A machine learning algorithm, on the other hand, can be trained to recognize the pattern of the organic shape, avoiding the need to create many tailored rules to attempt to approximate the allowable dimensions of the shape. As an added bonus, this algorithm works even if the product rapidly iterates through different designs.
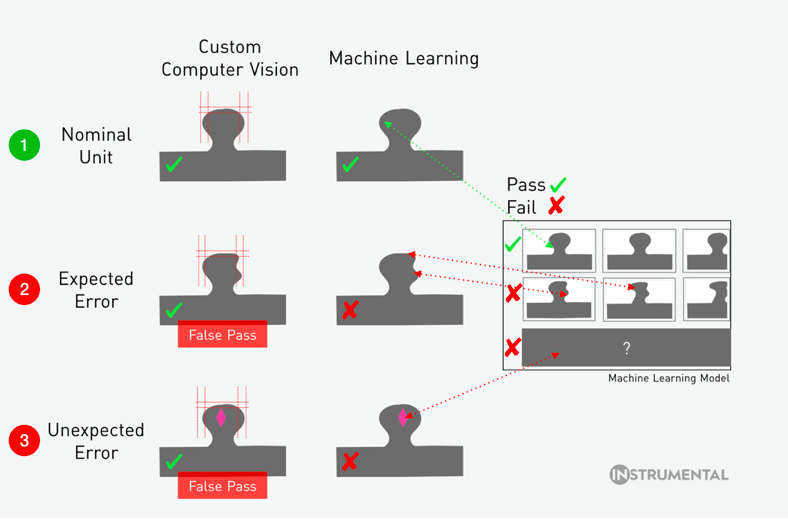
The first row features a “good” unit, and both computer vision and machine learning models correctly pass it. The second row features a “bad” unit with a smushed side, which incorrectly passes the computer vision guidelines for the shape. Machine learning, however, correctly prevents this unit from moving forward. On the third row, computer vision passes the unit based on shape, but fails to detect a severe discoloration, resulting in another false pass. Machine learning, in comparison, can identify that although the shape is good, the discoloration does not match other units, and flags the unit for a more focused inspection.
The Future of Manufacturing:
While computer vision has been used in automated inspection for decades, it is still ill-suited for many inspection scenarios — so much so that the majority of Final Vision Inspection on the assembly line is still done by trained human operators. Even with the best training and intentions, human inspectors will eventually get tired and start to make mistakes — the question is how soon.
Modern machine learning techniques, while still relatively nascent in the field of manufacturing, have the potential to reinvent automated inspection. These techniques will spot defects more like a human than a machine, but will analyze units in machine-time. With speed and self-learning capabilities, inspection will be something that isn’t just relegated to the beginning and end of the line: it will be at or after every step. With this much data, engineers will know exactly where cosmetic damage was done, which machine or operator went out of process, and when a unit should be pulled off of the line for repair. This kind of data is key to creating the insights required to build future assembly lines that are self-analyzing and self-correcting.

Anna-Katrina is the CEO and founder of Instrumental, a manufacturing data company that uses machine learning to find anomalies on consumer electronics assembly lines. She has two degrees in mechanical engineering from Stanford University, and went on to work as a Product Design Engineer at Apple. During her six years there, she designed mechanical components for three iPods and led system product design for the Apple Watch Series 1. After spending over 300 days in China finding and fixing issues on manufacturing lines, she started Instrumental to build an intelligent quality system to modernize manufacturing. Instrumental customers range from startups to Fortune 500s and span consumer electronics, apparel, and more.
Guest Blog by Lawrence Spracklen, VP of Engineering, Alpine Data
Looking Beyond the Algorithm — Operationalizing Data Science
I lead the engineering team at Alpine Data, an enterprise machine learning startup headquartered in San Francisco. We build an enterprise-grade data science platform that provides an end-to-end solution for data scientists, taking data scientists from problem definition through to model operationalization — where models can be seamlessly deployed to scoring engines running across the enterprise.
It’s this operationalization process that I want to discuss today. Data science is now a critical function of every enterprise, and there are significant expectations about the measurable value it should deliver. However, for an enterprise to benefit from the results of the data scientists, there needs to be an efficient mechanism to convey these insights to the broader enterprise in way that ensures that these findings are acted upon and the benefits realized.
While this sounds obvious, this requirement is frequently neglected. Too often the attention of the data science team is just focussed on leveraging ever more sophisticated algorithms and improving model accuracy and there is little thought of how these insights can change behavior across the enterprise.
While this operationalization can take many forms, including direct integration into CRM solutions, there is typically a general requirement to apply these models to real-time sources that are not necessarily integrated with the platform on which the models were trained. For instance, for predictive maintenance trained on a wealth of historical data on a Hadoop cluster, the models need to be applied to the real-time streams being emitted by the monitored machines. Similarly, for medical claims approval, network intrusion detection, or fraud detection, models trained on historical data needs to be applied to streams of incoming data and decisions made. Even in instances that don’t require real-time streaming support, data that needs to be scored on a daily, weekly or even monthly basis often resides on a different data platform than that holding the historical training data.
In many instances this is achieved by language specific exports. Models developed in Python/SciKit-learn can be exported and deployed to python-based scoring engines. Similarly, models created in R can be exported in an R specific format, and imported into R-based scoring engines. While this works, it requires a scoring engine paired with every possible model training environment. That’s fine for R and Python, but what about Spark, MADLib, Flink or TensorFlow? There’s a wide variety of environments used by data scientists to train models, and it’s important to avoid unnecessary proliferation in scoring engine environments.
Ideally, we should leverage a standardized serialization format for our modeling that can be widely shared. This was tried with limited success using PMML. PMML (or the Predictive Model Markup Language), was developed for developed for this purpose, and provides a platform independent way for expressing a wide variety of important machine learning models. And most ML toolkits provide support for exporting PMML models.
So why isn’t the use of PMML more prevalent? There are a number of different arguments that can be made, but I would argue that one of the strongest is that only represents a partial solution. Any scoring flow must not only specify the details of the trained model, but also the entire sequence of transformations that must be applying to the incoming data stream, as illustrated below.
Most scoring flows don’t simply involve applying the ML model directly to the incoming data to be scored. Rather, significant refinement of the incoming features (e.g. transformation, normalization, combination, and expansion) is required. Basic feature engineering can be encompassed by PMML. However, more often than not, the operations required can not be specified using PMML, and helper code has to be developed and deployed in conjunction with the PMML specification. This introduces the requirement for a Java, Python or C companion script, and eliminates many of the benefits associated with the use of PMML.
Happily, the Data Mining Group has been working to develop a new standard, called PFA (or the portable format for analytics). This standard benefits from the 20 years of experience we have gained with PMML, and ensures that a wide variety of transformation operations can be readily expressed in PFA, allowing the entire end-to-end scoring flow to be encapsulated in a single PFA document.
For folks that are interested in more details about PFA, details of the specification can be found here. Additionally, the Open Data Group have kindly provided an Apache licensed complete PFA implementation coded in Java and with Python wrappers, and I would encourage folks to download and experiment with PFA. Finally, a large part of the efforts behind driver broader adoption of PFA is to ensure that the most widely used OSS packages (e.g. scikit-learn or MLlib) provide support for PFA — please let us know if you are interested in getting involved in this effort!

Lawrence Spracklen leads engineering at Alpine Data. He is tasked with the development of Alpine’s advanced analytics platform. Prior to joining Alpine, Lawrence worked at Ayasdi as both VP of Engineering and Chief Architect. Before this, Lawrence spent over a decade working at Sun Microsystems, Nvidia and VMware, where he led teams focused on the intersection of hardware architecture and software performance and scalability. Lawrence holds a Ph.D. in Electronic engineering from the University of Aberdeen, a B.Sc. in Computational Physics from the University of York and has been issued over 50 US patents.
Interview with Adam Omidpanah, Biostatistician, Washington State University, by Sarah Braden
One of our Program Committee members, Sarah Braden, recently interviewed Adam Omidpanah, Biostatistician, Washington State University. This interview covers how recent advances in machine learning have impacted research in health care delivery.
SB) Tell us briefly about yourself and your work.
AO) I am a biostatistician with Washington State University’s college of nursing. I work with a variety of junior collaborators helping them with study design, data analysis, and manuscript preparation. Our work mainly focuses on health care delivery and disparities in marginal US populations, particularly American Indians and Alaska Natives. One of the greatest challenges to my work is shaping a complex causal model which incorporates psychosocial medicine with overt medical conditions, such as the relation between sleep and depression or PTSD and diabetes complications.
SB) This past month Google released a paper on ArXiv (https://arxiv.org/abs/1703.02442) demonstrating a convolutional neural network (CNN) model that has better small tumor detection rates compared to human pathologists. The context for this work was improving breast cancer metastasis detection in lymph nodes. With better metastasis detection more appropriate patient treatment plans could be chosen, and potentially improve patient outcomes. How are other advances in Machine Learning improving the accuracy of cancer diagnoses and risk prediction?
AO) I think ROC regression is a promising area of research. On one hand, ROC regression combines covariates to directly maximize an ROC curve, but its operating characteristics are very irregular. I think boosting and bagging are also promising, and it is only a matter of time before a diagnostic tool is developed that requires knowledge about several hundred genes simultaneously. I am also happy that risk stratification table indices like the integrated discrimination index, have recently fallen out of favor. I always found their performance to be overly sensitive to assumptions, and recent work from Dr. Katie Kerr and Dr. Margaret Pepe have proven this (and other issues) to be a cause for concern.
SB) What are the barriers to introducing machine learning into clinical practice? Is there a protocol for using machine learning models in the field of oncology?
AO) Randomized clinical trials are a gold standard for demonstrating effectiveness of any new cancer detection or treatment tool. Any machinery involving ML algorithms should be subjected to the same rigorous testing, and also confirmed in secondary trials to reduce false positive findings. In that sense I don’t see these as barriers. The clinical perception toward these tools is very positive: generally, there is a desire to reduce human error. The protocol for using machine learning model is pragmatic.
SB) What datasets are openly available for researchers to work on cancer risk prediction?
AO) SEER is perhaps the most widely known. The Center For Medicare Services (CMS) has recently merged SEER data with Medicare data and provided a 10% subsample of the US population without cancer. However, I would encourage interested investigators to research the National Cancer Institute (NCI)’s many accessible databases. Open data are useful, but closed data aren’t inaccessible.
SB) How do concerns about data privacy affect Machine Learning research in oncology?
AO) Most concerns relate specifically to the technology: genetics in particular has been a problematic area of research. Biospecimen donation rates are relatively low, especially for racial and ethnic minorities. And yet, these are the people often most adversely affected by cancer. Promoting biospecimen donation among racial and ethnic minorities could improve precision medicine and reduce disparities.
SB) Clinical science datasets often have large p, small n problems where the number of predictor variables (or features) is larger than the number of observations. Missing data and unbalanced classes are other common issues. What techniques do you use to overcome these challenges in your own work?
AO) An unpopular approach to p >> n is to simply refine the scope of the problem. Very rarely do I encounter a dataset where all features can be assigned equal weight. Combining relevant features in practical ways, and excluding others which have no relation to a pre-specified scientific question usually clearly points to a way forward. Missing data methods and unbalanced classes, while unrelated, all have methods involving applying high dimensional prediction algorithms to either impute or propensity match, thus improving the performance of regression models using those data. Recently I’ve had some success estimating such a high dimensional prediction algorithm using, simply, log linear models with splines and BIC for model selection.

Adam Omidpanah is a biostatistician whose interest in machine learning began during his graduate studies. Adam holds a Bachelors of Science, Mathematics from Portland State University and a Masters of Science, Biostatistics from University of Washington.

Sarah Braden is currently a Data Scientist at the startup HireIQ Solutions, Inc. There she specializes in developing predictive models for HireIQ’s automated interviewing platform. She also writes tools for HireIQ using automated speech recognition. Sarah is a fan of open source technology. She holds a PhD in Geological Sciences from the School of Earth and Space Exploration at Arizona State University and a Bachelors in Physics from Northwestern University.
Interview with Halim Abbas, VP of Data Science, Cognoa, by Alex Korbonits
One of our Program Committee members, Alex Korbonits, recently interviewed Halim Abbas, Vice President of Data Science at Cognoa, on how recent advances in machine learning have impacted research in childhood development, and his work at Cognoa.
AK) Recently, Nature published a groundbreaking article on the application of advanced machine learning techniques to model early childhood development. Specifically, researchers leveraged artificial neural networks to predict diagnoses for autism with high sensitivity well before behavioral characteristics correlated with ASD usually appear. How have recent advances in machine learning impacted cognitive clinical science generally and research in early childhood development specifically?
HA) Machine learning is a transformative technology that has helped disrupt or completely reinvent every vertical it has been applied to (including health and wellness) in the last decade or two. Cognitive clinical science is relatively late to the party and is only recently beginning to benefit from the power of ML. From leveraging phenotypic data toward reliable assessment, to mining genomic data for meaningful signal, or even building bridges between the two sources, the sky’s the limit.
AK) What excites you the most about applying machine learning to early childhood development?
HA) I worked across many verticals before joining Cognoa. It is hard to beat the excitement you feel when working on a solution to put parents’ minds at ease, or alert them to take action early enough to make a meaningful difference in their children’s quality of life. The field is ripe for technological advancement, and the potential benefit couldn’t be more urgently needed. With developmental delay affecting 1 in 6 U.S. children and a national shortage of diagnosticians, anxious parents often wait over a year to get in to see a specialist; this means that many children miss out on important early interventional therapies. Being in a position to help with a problem so personal to so many people feels like such a privilege.
AK) With all prediction problems, there is a natural tension between maximizing accuracy vs. maintaining interpretability. At Cognoa, what kinds of prediction problems do you encounter that require interpretability? Are there some prediction problems for which black-box models are acceptable or encouraged?
HA) Anything we build that is designed to interact with or influence the medical diagnostic process is required to be interpretable by medical professionals, and understandably so. At a minimum, this means that the most relevant factors to the prediction must be knowable, and the features be tied to meaningful semantic concepts. While this makes certain ML techniques (like PCA or SVM) unfavorable, it doesn’t pose an insurmountable limitation in practice. Models that are peripheral to the diagnostic process (like patient clustering, signal processing, anomaly detection, and time series analysis techniques) tend to remain “black-boxy”.
AK) How do you and your team communicate complex machine learning concepts to parents and cognitive clinical scientists?
HA) The trick is to keep the messaging firmly grounded in the application domain and avoid drifting into specifics that are not directly interpretable in the problem space. A parent isn’t interested in learning whether the underlying screening model was trained with ensemble techniques or which kernel method was used in the SVM classifier. The aspects that matter in this case include meaningful measures of reliability of assessment and information about the factors that significantly contributed to the conclusion. We also found that our users greatly value any information we can give them about the statistical significance of their experience relative to their respective demographic bin. Decile placements, false positive/negative rates, and confidence ranges are good examples.
AK) To what extent is further research in early childhood development influenced by the use of predictive machine learning models?
HA) Today, the typical age of diagnosis for a condition like autism remains over 4, even though it has long been established that earlier diagnosis dramatically improves the impact of intervention. A new breed of clinical science and data science experts are currently busy at work looking for ways to put predictive modeling at work on younger and younger children. The younger they are, the more subtle and fragmented the relevant signals are, which puts the challenge right up the alley of data-driven modeling. The fruit of this wide collaboration might be reliably diagnosing developmental conditions within the first year of life.
AK) With many medical applications, modeling can be extremely difficult due to the so-called “p >> n” problem, where you may have very rich “wide” data but not enough instances to learn effectively. Furthermore, you may have to rely on inconclusive screening, missing data, or noisy measurements. Do you regularly experience these phenomena at Cognoa, and if so, do you have any preferred techniques to circumvent them?
HA) We call it the wide-and-shallow dataset problem, and it is perennial in the field of clinical science. One approach we use to mitigate that limitation is to avail ourselves from two different but complementary sources of data: Clinical patient records are labeled by experts and hence relatively clean and reliable, but sparse, shallow, heavily unbalanced, and very expensive to acquire. Data we accrue from our app user-base is orders of magnitude more voluminous, cheaper to amass, timelier and denser, but inherently noisy and relatively unreliable. At Cognoa we developed a multi-pronged approach in which each data source is put to proper use. For example, we might mine our user-base data to better understand the dimensions and/or segments that are most relevant to the problem at hand, and the nature of the (heavily non-linear) relationships and dependencies interconnecting the relevant dimensions. These insights would then influence the way we seek to collect, filter, and balance clinical patient records used for training our behavioral health screening models.
*We would love to see you at our next MLconf in New York. Mention “Halim18” and save 18% on a ticket to the event!

Halim Abbas, VP of Data Science, Cognoa, is a high tech innovator who spearheaded world-class data science projects at game changing tech firms such as eBay and Quixey. Formally educated in Machine Learning, his professional expertise span Information Retrieval, Natural Language Processing, and Big Data. Halim has a proven track record of applying state of the art data science techniques across industry verticals such as eCommerce, web & mobile services, airline, BioPharma, and the medical technology industry.
He currently leads the Data Science department at Cognoa, a data driven behavioral health care Palo Alto startup.

Alex Korbonits is a Data Scientist at Remitly, Inc., where he works extensively on feature extraction and putting machine learning models into production. Outside of work, he loves Kaggle competitions, is diving deep into topological data analysis, and is exploring machine learning on GPUs. Alex is a graduate of the University of Chicago with degrees in Mathematics and Economics.
Call For Speakers- 2017 Events
MLconf is calling for speakers for 2017 events!
- Algorithms that have graduated academic conferences such as NIPS, ICML, etc and have proven to be effective, robust and scalable in production
- Novel data science practices, such as data transformations, new data sources, novel representations, etc
- Machine Learning/AI case studies (Lessons learned), demonstrating challenges in the wild and how to handle them in a new way
- New platforms, tools for machine learning. Emphasis should be given on the technical challenges, benchmarks and motivation for the development
- New business practices, for managing, growing data science teams and expanding machine learning to new domains
- Tutorials and novel ways of presenting and simplifying machine learning domains, including: deep learning, kernel methods, bayesian nonparametrics, tensor algebra, etc
- Up and coming areas of machine learning that you think will dominate the industry in the future, such as probabilistic programming etc.
Topics we’re looking for:
- Natural Language Processing
- Deep Learning
- Reinforcement Learning
- Neural Turing Machines/Neural Theorem Provers
- Generative Models
- Probabilistic Programming
- Probabilistic Logic and Reasoning
- Chatbots/ ALL Bots
- Bayesian Inference
- One Shot Learning
- Markov Logic Networks
- Structure Learning
- Synthetic Art, Biology
- Ethics in Machine Learning
- Sketching Randomized Algorithms
- Game Theory
- Community Detection
- Large-Scale Clustering
- Time Series
- Image Analysis
- Bayesian Non-Parametrics
- Topic Models
Submit Abstract – The deadline schedule is as follows:
- MLconf NYC – 01/31/2017 Submission Deadline
- MLconf SEA – 03/01/2017 Submission Deadline
- MLconf ATL – 06/01/2017 Submission Deadline
- MLconf SF – 07/01/2017 Submission Deadline
The selection of the presentation will be based on:
- Clarity and novelty of the presentation
- Diversity of the topics for the conference
- Speaker’s experience in the industry
The 2016 Winner of the MLconf Industry Impact Student Research Award, Sponsored by Google, Has Been Announced!
The winner of the 2016 MLconf Industry Impact Student Research Award, which is sponsored by Google has been announced. Our committee has reviewed several nominees and found Tianqi Chen’s research on XGBoost and MXNet to be the most impactful and interesting for future developments in industry.
Tianqi Chen is the winner of the 2016 MLconf Industry Impact Student Research Award! This announcement was made on Friday, November 11th, 2016 in San Francisco. Tianqi accepted via a video acceptance speech (available here).
In 2015, there were 2 winners of the award, including Viriginia Smith (UC Berkeley) whom presented on November 11, 2016 at MLconf SF and Furong Huang (UC Irvine) whom presented at MLconf NYC in April 2016.
Tianqi has been invited to present his work on XGBoost in Seattle at MLconf in 2017. His advisor, Dr. Carlos Guestrin, has presented at MLconf numerous times as well.
Tianqi works at the intersection of learning and systems. He has built many scalable learning systems. His research focuses on scalable boosted trees and work on a package XGBoost, which is widely used for competitive ML and in the industry for supervised learning problems where you train data to predict another variable because it provides parallelized boosted trees that run in an efficient and accurate way. XGBoost is available in many distributed environments for production such as Hadoop, MPI, SGE, Flink, & Spark, and in many preferred languages such as python, R, Julia, java, scala. The framework constructs tree ensembles. It is not easy to train trees at once, so XGBoost takes an additive model and trains one tree, uses the information from it and adds another tree. Then, after the tree ensembles are created, the model needs to be regularized. First, the complexity is defined in order to regularize the model and better understand what information is being learned. Regularization is one part most tree packages treat less carefully, or ignore. This is because the traditional treatment of tree learning emphasized improving impurity, while complexity control was left to heuristics. By defining it formally, we understand it better and it works well in practice. One can derive a structure score and a goodness-of-fit measure for the tree ensemble.
Tianqi is also well-known for his contribution to work on MXNet. MX stands for mix and minimize and is a dynamic dependency scheduler that automatically parallelizes both declarative and imperative operations. The heart of MXNet is NNMVM an intermediate layer just like LLVM. the abstraction to NNVm allows several just in time code optimization s that significantly boost the performance. MXNet as a competitor to TensorFlow is widely recognized as it has been heavily invested in by Amazon.

Bio:
Tianqi holds a bachelor’s degree in Computer Science from Shanghai Jiao Tong University, where he was a member of ACM Class, now part of Zhiyuan College in SJTU. He did his master’s degree at Changhai Jiao Tong University in China on Apex Data and Knowledge Management before joining the University of Washington as a PhD. He has had several prestigious internships and has been a visiting scholar including: Google on the Brain Team, at Graphlab authoring the boosted tree and neural net toolkit, at Microsoft Research Asia in the Machine Learning Group, and the Digital Enterprise Institute in Galway Ireland. What really excites Tianqi is what processes and goals can be enabled when we bring advanced learning techniques and systems together. He pushes the envelope on deep learning, knowledge transfer and lifelong learning. His PhD is supported by a Google PhD Fellowship.